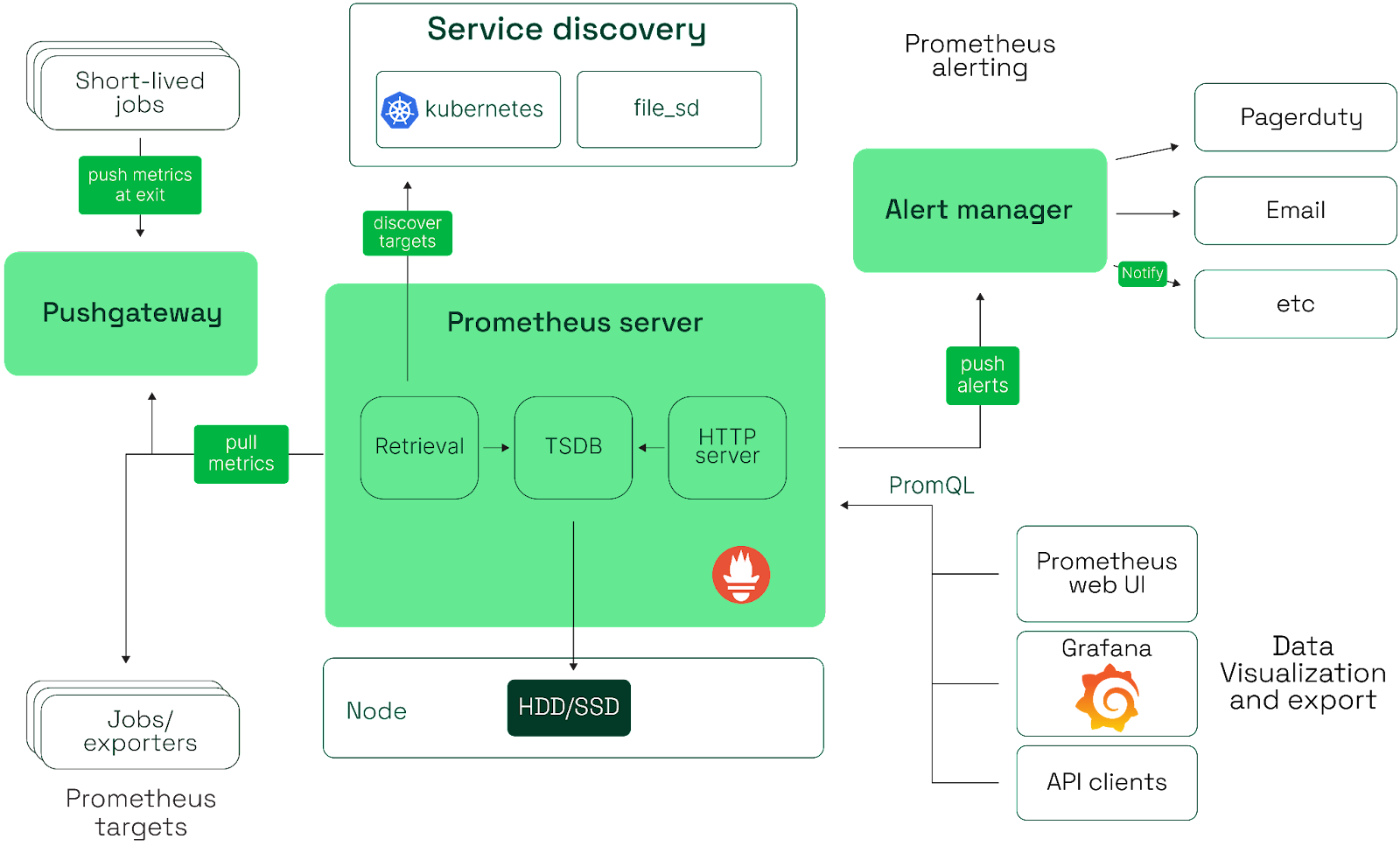
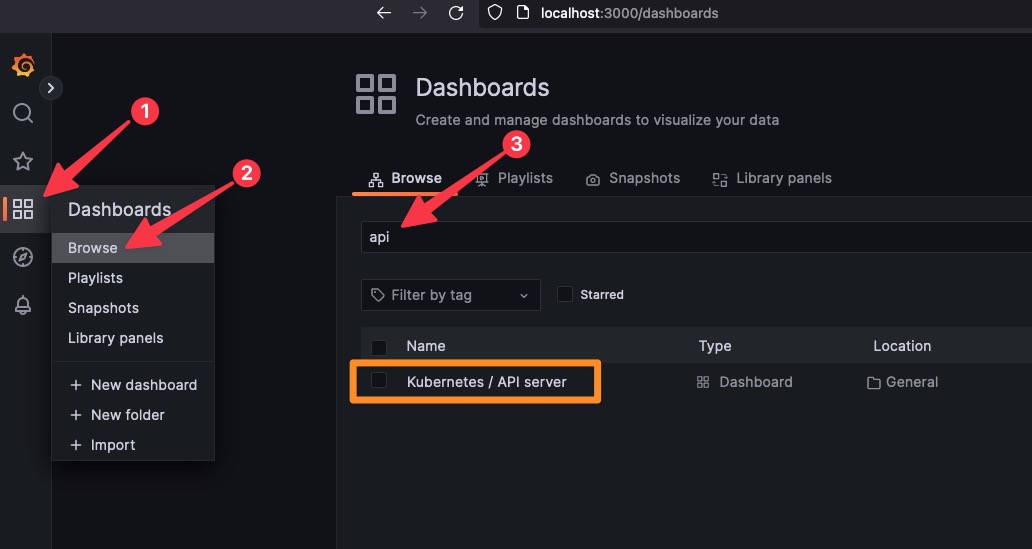
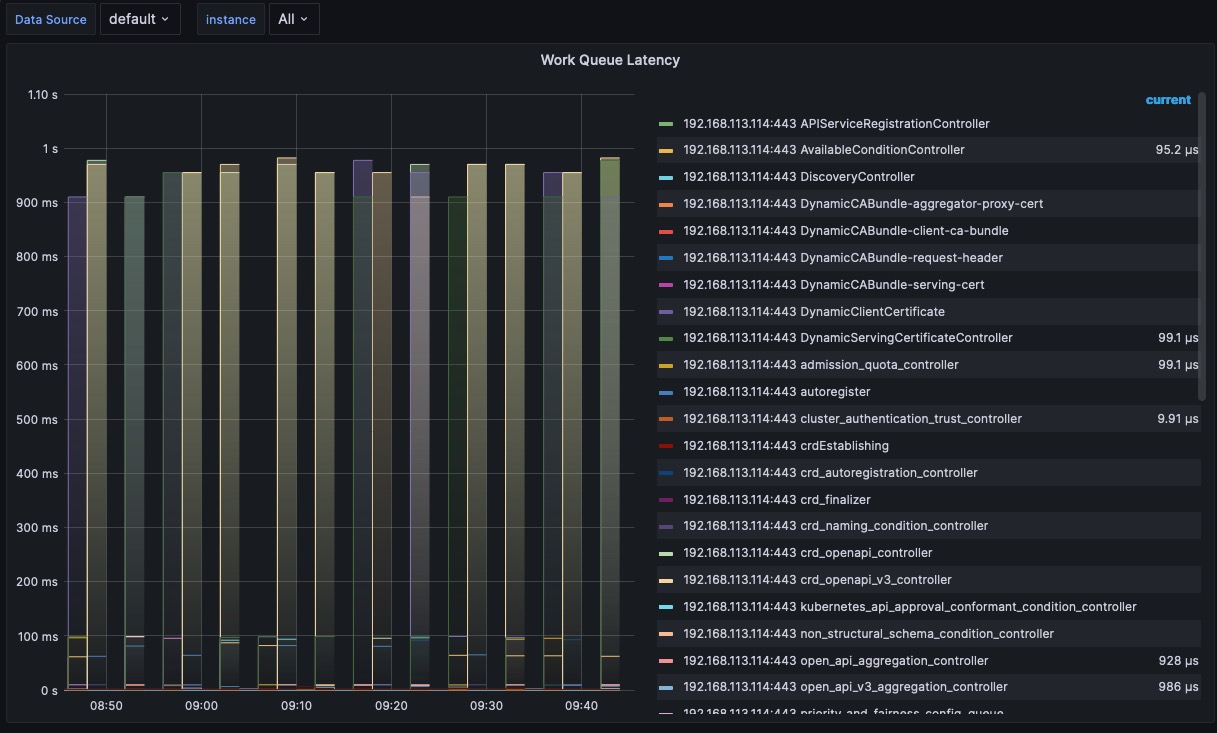
The following sections explore four essential Kubernetes monitoring best practices necessary to ensure optimal workload performance and availability.
Implement a comprehensive monitoring strategy.
Include all layers:
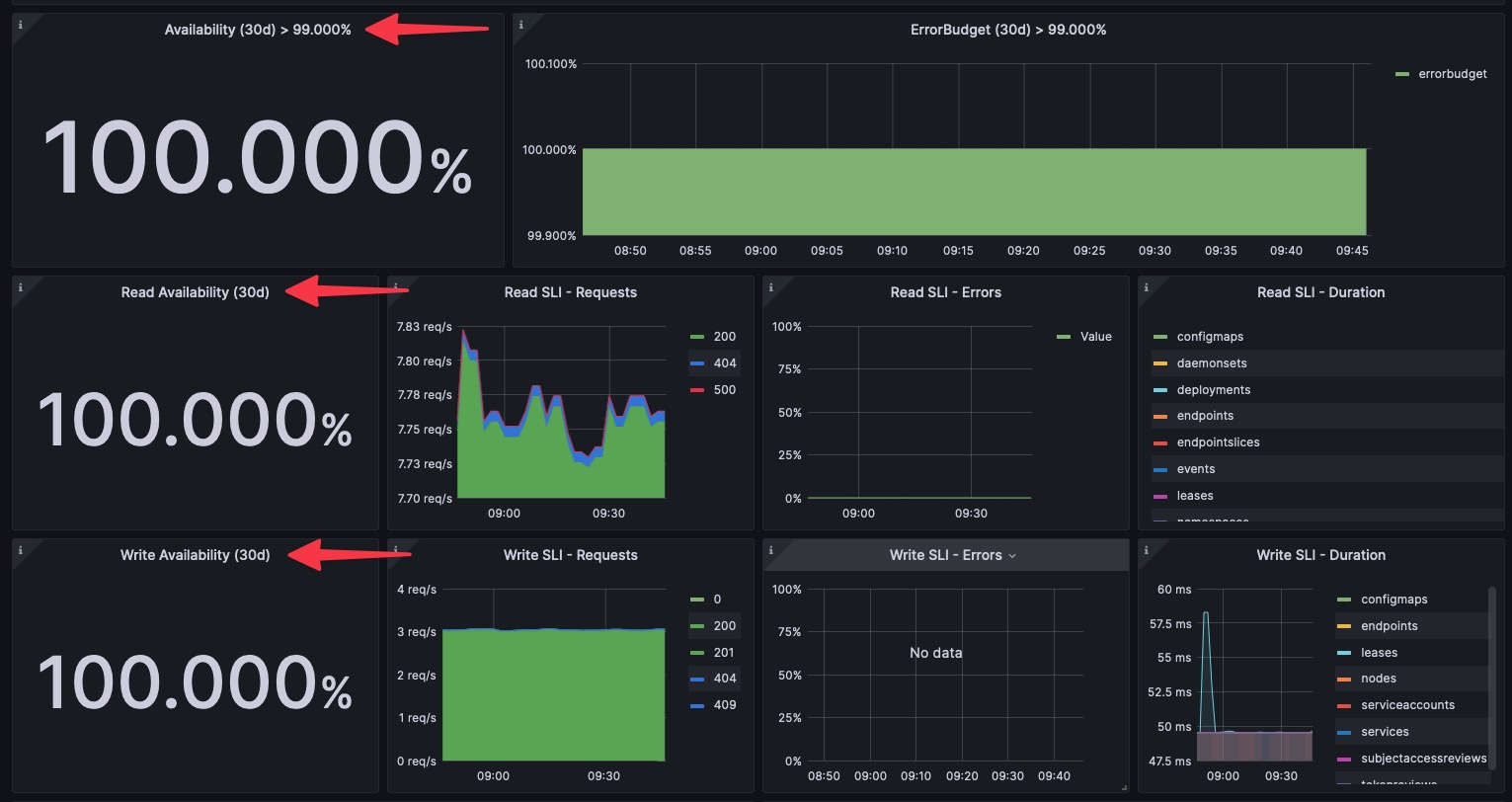
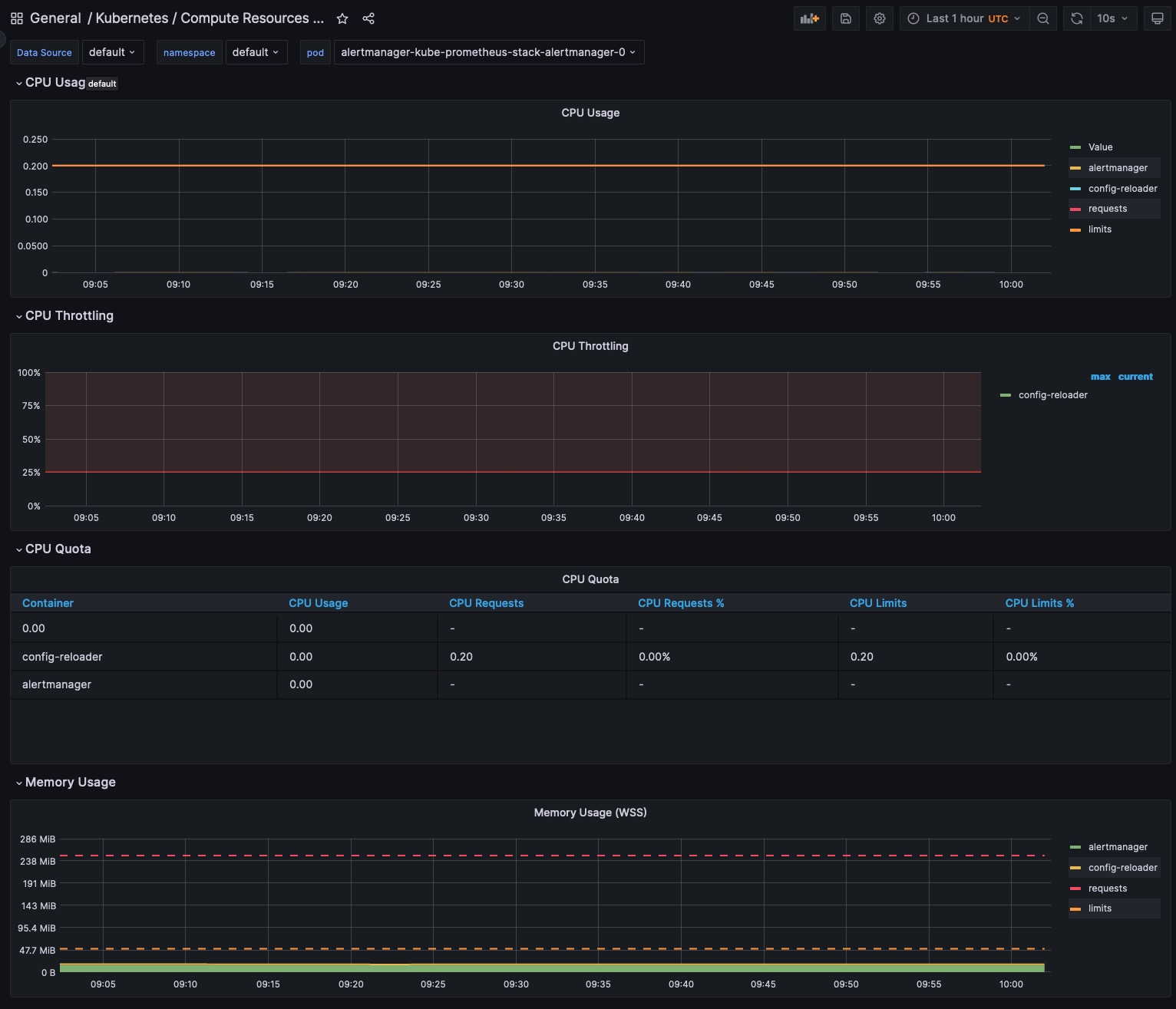
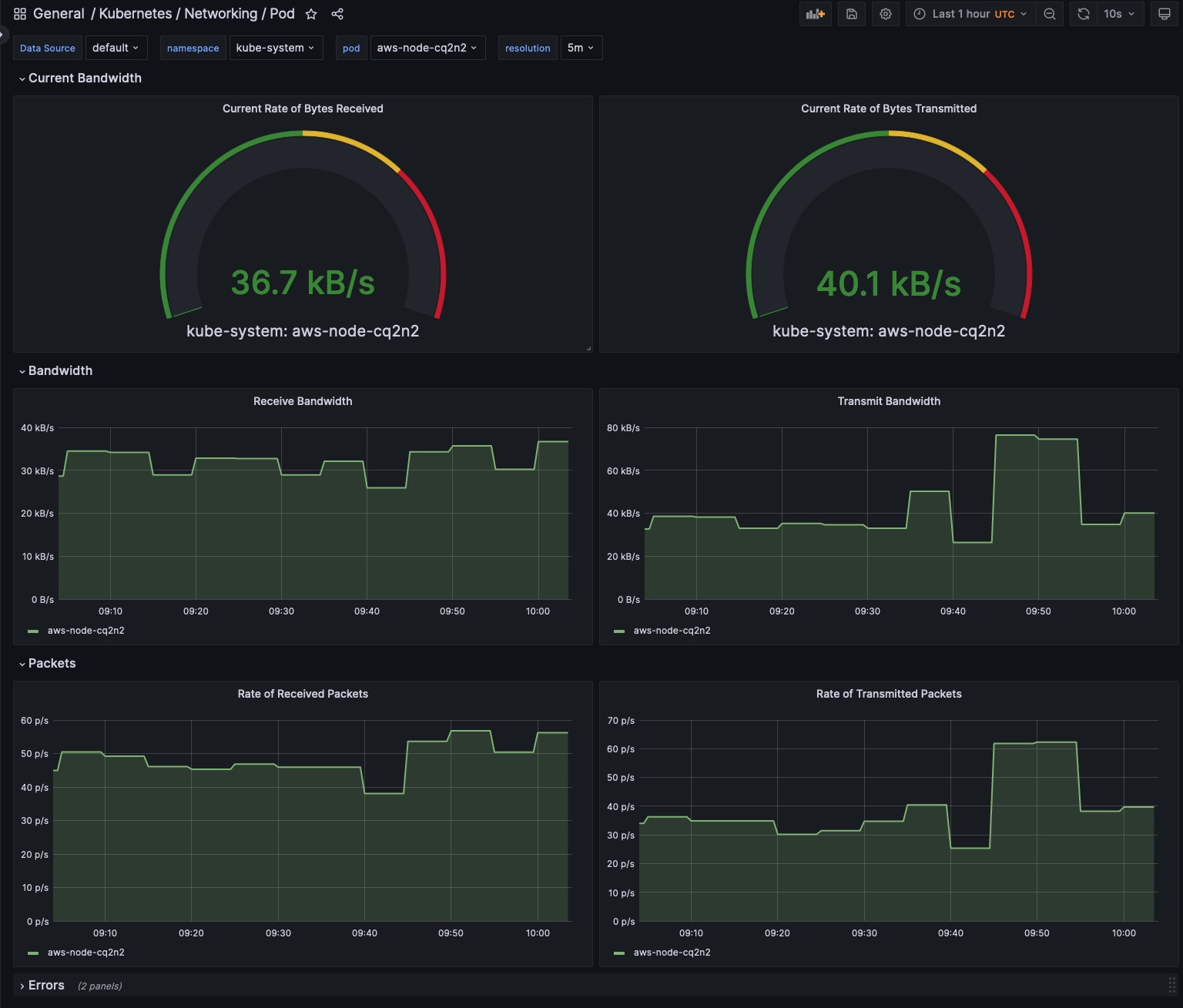
Your monitoring strategy should cover every layer: infrastructure, platform, and application-level metrics. For instance, infrastructure metrics like node CPU or memory usage, platform metrics such as Kubernetes events or errors, and application metrics such as request count or error rate. This holistic approach provides an end-to-end view of your environment, enabling data-driven decisions and proactive issue resolution. Observing all layers lets you quickly pinpoint whether an issue originates from the infrastructure, the platform, or the application itself.
Address cluster-wide and granular metrics:
Collect and analyze metrics at the cluster level (e.g., cluster state, resource availability) and more granular levels (e.g., node-level resource usage, pod status). For instance, monitoring node-level metrics can swiftly identify a spike in CPU usage at a specific node, enabling faster issue mitigation. This combination of comprehensive and granular focus helps uncover system-wide patterns and individual discrepancies, allowing you to optimize resource usage and mitigate issues early.
Ensure accurate and timely data collection.
Configure metric scraping intervals:
Adjusting Prometheus metric scraping intervals to suit your environment's needs is crucial. For example, a microservices application with fluctuating workloads might require shorter scraping intervals for near real-time insights. Nevertheless, the increased system overhead caused by more frequent scraping should be considered and balanced against your monitoring requirements. Regular, reliable data collection is vital to an effective monitoring strategy.
Verify metric accuracy through validation checks:
Implement validation checks to verify the accuracy and consistency of collected metrics. For instance, cross-verifying system CPU usage metrics with process-level CPU usage metrics ensures data consistency and validity. These steps help avert false alarms, ensure data reliability, and provide confidence in your system analysis and decision-making processes.
Establish proactive alerting and incident response.
Define alert thresholds and escalation policies:
Setting alert thresholds based on your environment's requirements is essential. For example, you might set an alert threshold at 80% CPU usage if a particular pod consistently peaks at this level. You should also define Escalation policies alongside immediate notifications to the monitoring team if critical alerts are not addressed promptly. Effective alert management helps avoid system downtime and promotes efficient incident response.
Integrate with incident management tools:
Connecting your monitoring solution with tools like PagerDuty or OpsGenie enhances the incident response process. For instance, critical alerts could automatically create incidents in these tools, notifying the relevant team and triggering the incident resolution process. This integration simplifies alert management, reduces manual effort, and improves system reliability.
Utilize cluster cost monitoring tools.
Integrate Kubecost into your monitoring solution to track and optimize the cost of running your Kubernetes clusters. Kubecost can provide insights into resource usage per namespace, pod, container, and/or labels, helping identify inefficiencies, such as underutilized resources that you could downsize to save costs. This cost monitoring enhances financial visibility and promotes cost-effective resource management.
Combining Kubecost with your existing monitoring tools gives you a comprehensive understanding of your Kubernetes environment's performance and cost-related aspects.
This overview includes monitoring metrics and cost information, enabling informed resource management and cost control decisions. It leads to more efficient operations and aids in maintaining a balance between performance and cost-effectiveness.
The instructions for integrating with Prometheus are provided here.