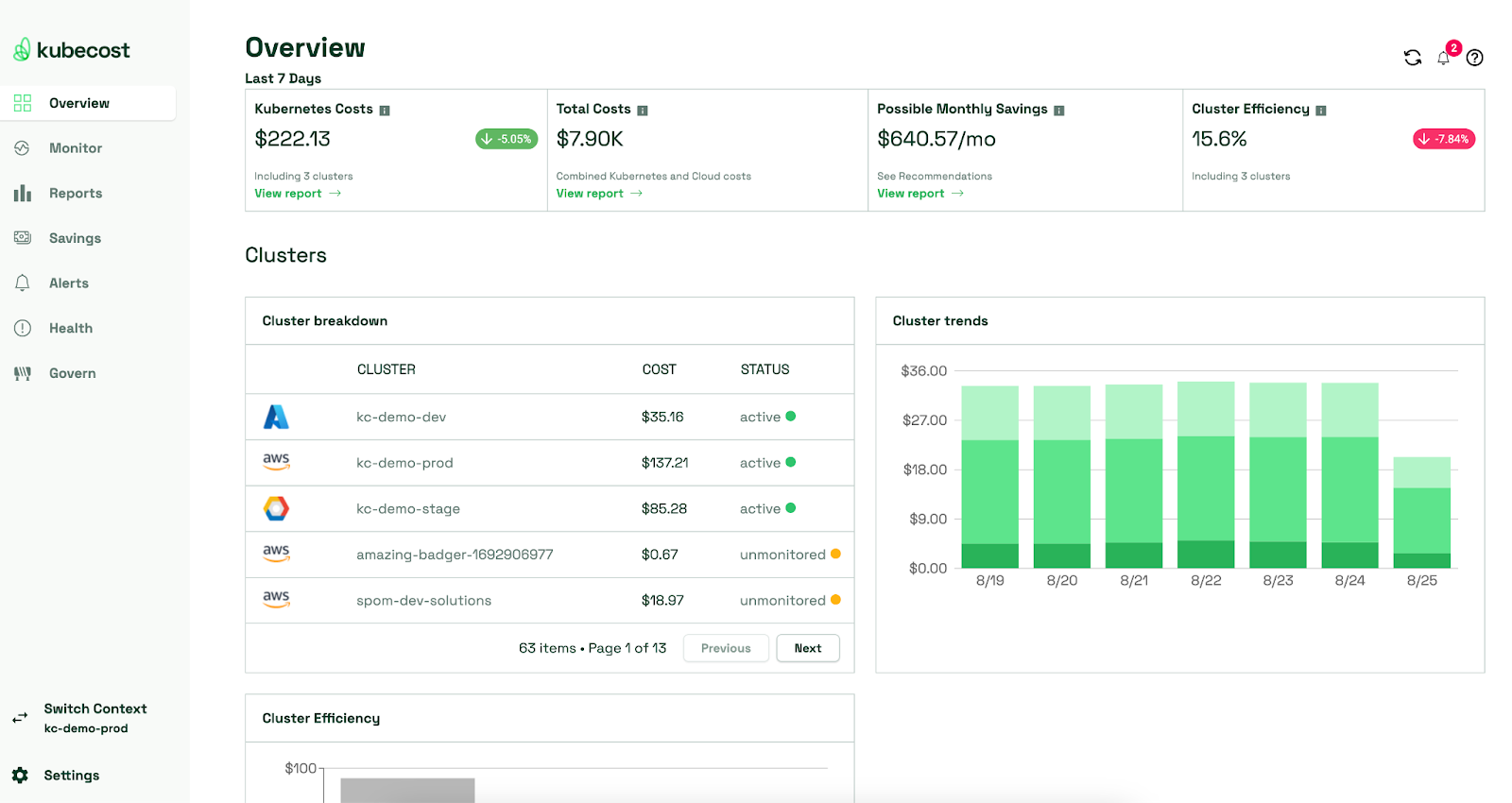
In the realm of cloud-native architecture, Kubernetes is the de facto standard for container orchestration. Its ability to scale, manage, and automate containerized applications has revolutionized how we deploy and control software.
However, while Kubernetes simplifies many aspects of container management, it also introduces new challenges, particularly regarding monitoring. Effective Kubernetes monitoring is crucial for maintaining the health, performance, and security of your containerized applications.
This article aims to comprehensively illustrate Kubernetes monitoring, its significance, and the essential aspects you should monitor. We explore the tools and best practices for monitoring Kubernetes clusters and their applications. By the end of this article, you’ll be equipped with the knowledge and tools needed to ensure that your cloud-native ecosystem operates seamlessly.