In the dynamic world of containerized applications, Kubernetes has become the go-to orchestrator. However, ensuring that your applications perform optimally and remain cost-efficient is no small feat.
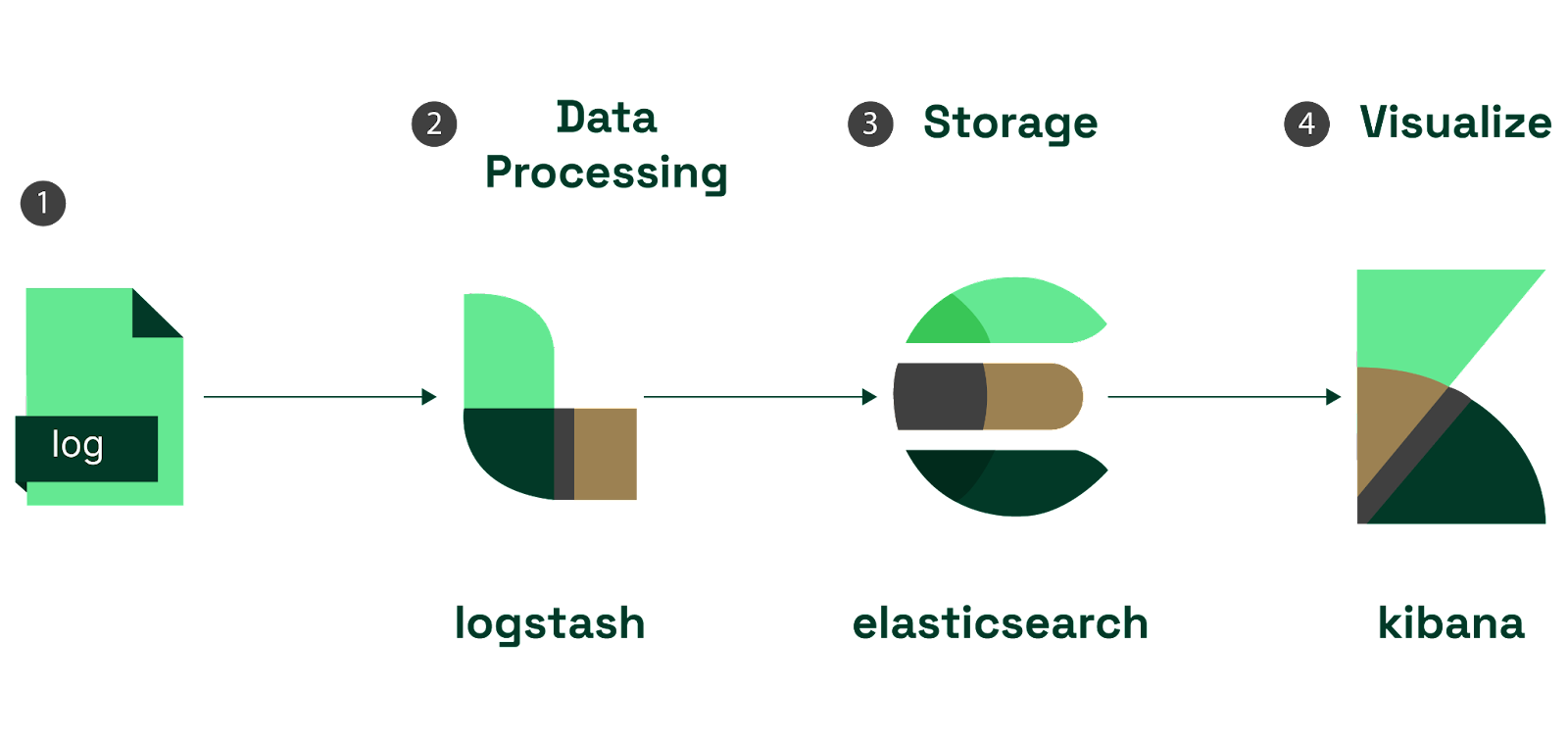
Traditional monitoring tools fall short when it comes to Kubernetes. The dynamic and ephemeral nature of containers makes it challenging to keep track of what's happening in your cluster without observability. Here’s why it matters:
- Quick issue resolution: When an issue arises, observability tools provide the data needed for rapid troubleshooting and resolution, reducing downtime.
- Performance optimization: Observability helps you identify performance bottlenecks and resource inefficiencies, enabling you to optimize your applications.
- Resource efficiency: By understanding resource usage, you can right-size your containers and clusters, minimizing unnecessary costs.
- Security: Logs and traces can assist in detecting and responding to security incidents, helping you maintain a secure environment.
In this article, we delve deeper into the essential components of Kubernetes observability, provide practical guidance on their implementation, and explore how observability contributes to cost management within your Kubernetes deployments. We also offer hands-on guidance and best practices to ensure that your Kubernetes deployments run smoothly, maintaining cost-effectiveness and achieving operational excellence. By the end of this article, you’ll have the insights and tools you need to optimize performance while keeping your Kubernetes ecosystem running efficiently and cost-effectively.