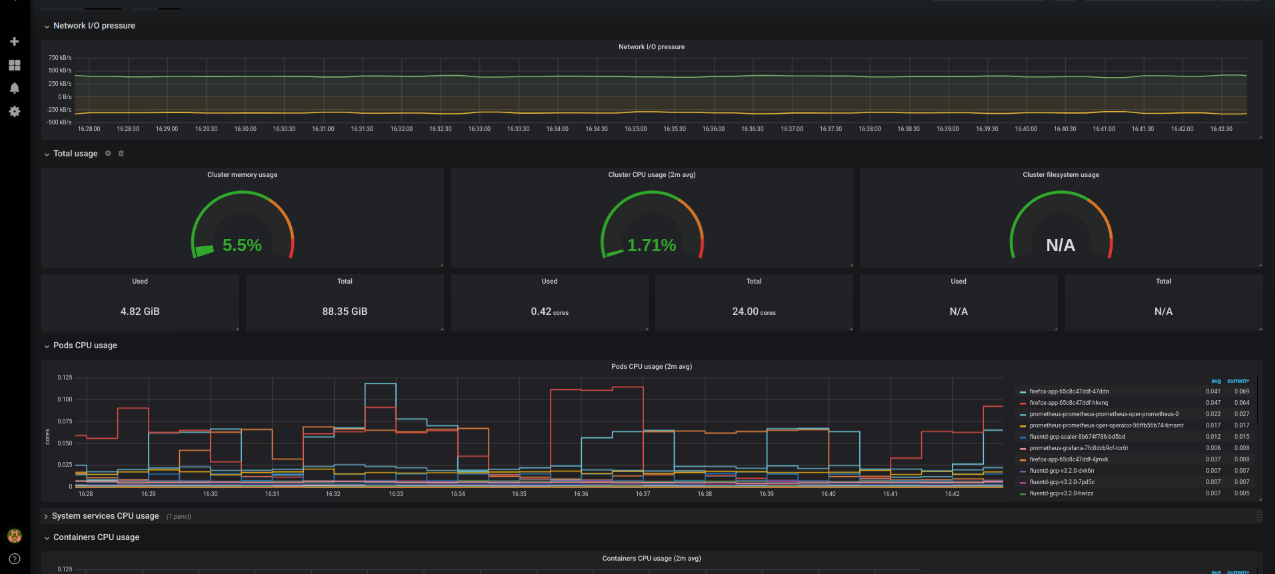
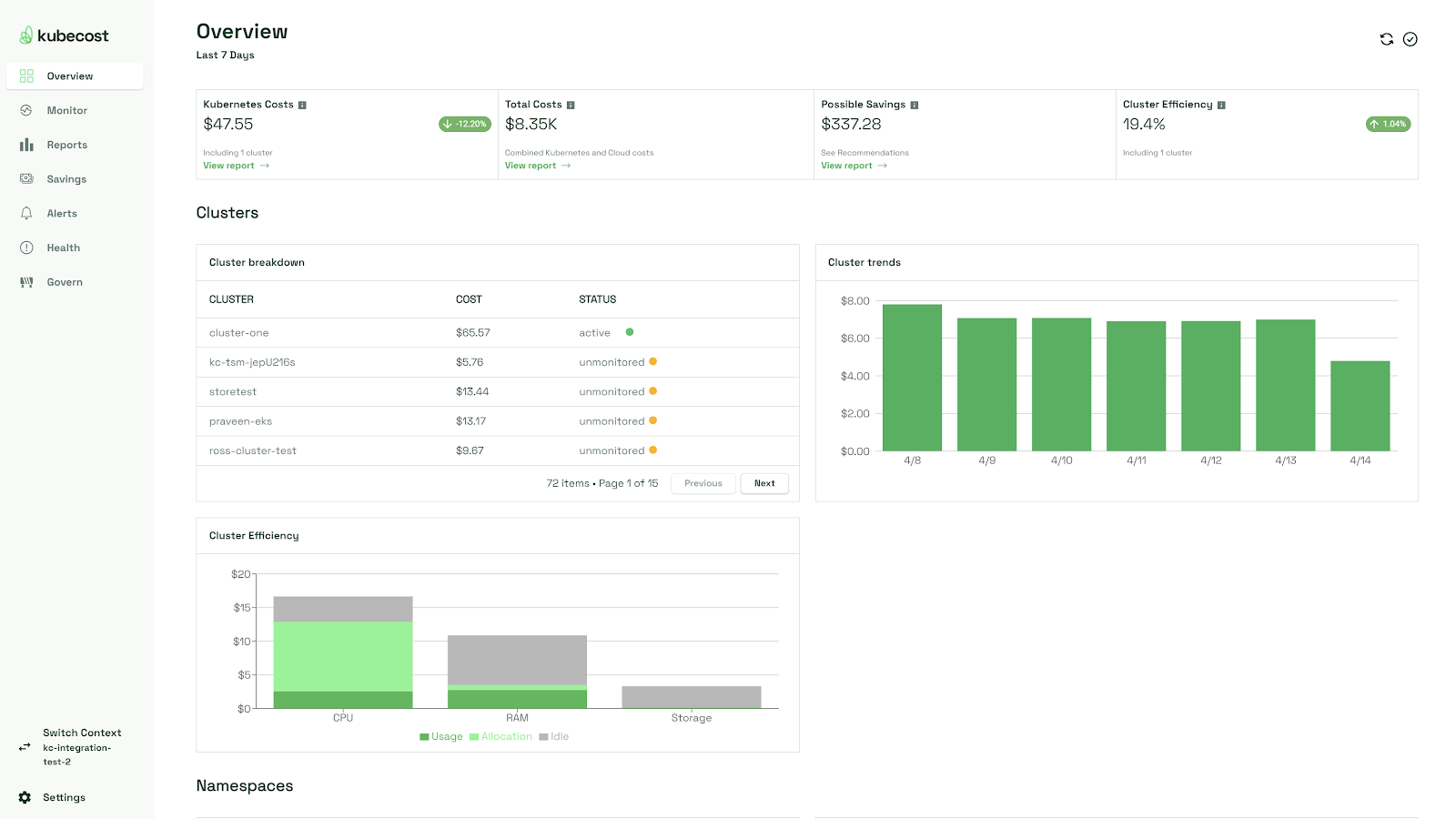
There are many different components of an EKS cluster that can produce valuable logs and metrics. This section will help administrators understand what components of an EKS cluster require monitoring, what type of data they generate, and how teams can collect the data.
EKS cluster control plane
The control plane of a Kubernetes cluster includes many components responsible for operating the cluster. It is composed of Master Nodes and ETCD Nodes, which are compute instances hosting various binaries required for any standard Kubernetes cluster to function, such as the Kube Scheduler and Kube API Server. EKS is a managed service, so the control plane Nodes are hidden from the user and handled by EKS. However, metrics and logs are still exposed by the control plane binaries to assist administrators with understanding how their control plane is operating.
Administrators need to understand the components running in the EKS control plane and what data they can expose. This information is critical for troubleshooting issues such as performance bottlenecks and security auditing.
The five critical components of an EKS cluster control plane are: API server, Kube Controller Manager, Cloud Controller Manager, Kube Scheduler, and etcd. Let’s take a closer look at each one.
API server
This binary is the entry point for the cluster. It is responsible for responding to requests for cluster information (such as when you run Kubectl commands) or creating/updating objects. Kubernetes objects can only be modified by sending requests through the API Server.
The API Server exposes Prometheus metrics such as how many requests it receives, average processing time, and response codes. API Server metrics provide administrators with insight into how well the API Server is performing, whether the cluster's control plane is handling the current volume of requests, and whether any scaling issues are occurring for the control plane Nodes.
Alongside the Prometheus metrics, the API Server also exposes multiple log files providing additional insight into cluster operations:
- API: These logs detail the flags passed as arguments to the API Server binary during startup. Administrators cannot modify these flags, but having insight into what flags are enabled will help to understand the cluster's configuration provided by EKS (such as which Admission Controllers are enabled by default).
- Audit: These logs are critical for security analysis. They detail every request submitted to the API Server, what resources were viewed/created/modified, and what user performed the action. This log is essential for auditing access to the cluster and performing analysis, such as determining which user modified a particular resource.
- Authenticator: While the above Audit log provides details about a Kubernetes user's requests, the Authenticator logs give details on which specific IAM Role or IAM User accessed the cluster. Since EKS implements IAM authentication for human users to access the cluster, correlating cluster actions with IAM entities is another aspect of security analysis.
Kube Controller Manager
This component is responsible for reconciling the desired state for the cluster for all standard objects like Pods, Nodes, Deployments, Services, etc. It continuously monitors the state of the cluster and reconciles resources to match the desired state specified in the Kubernetes object schema.
EKS exposes a log file (called controllerManager) for this control plane component, which contains details about the component's ongoing operations. This log file provides a lot of detail, which is quite helpful when investigating the sequences of events occurring in the cluster. For example, the log file below shows some log entries of a freshly created EKS cluster. EKS creates a CoreDNS deployment with two replicas by default. We can see Kube Controller Manager detecting the Deployment for CoreDNS, creating a corresponding ReplicaSet, and then launching new Pods. The log data from this component helps investigate any events occurring in the cluster involving resource reconciliation.
replica_set.go] "Too few replicas" replicaSet="kube-system/coredns-67f8f59c6c" need=2 creating=2
event.go] "Event occurred" object="kube-system/coredns" kind="Deployment" reason="ScalingReplicaSet" message="Scaled up replica set coredns-67f8f59c6c to 2"
event.go] "Event occurred" object="kube-system/coredns-67f8f59c6c" kind="ReplicaSet" reason="SuccessfulCreate" message="Created pod: coredns-67f8f59c6c-5fm42"
The Kube Controller Manager also exposes Prometheus metrics, such as the count of pending operations (workqueue_depth) and latency per operation (workqueue_queue_duration_seconds_bucket). Metrics for this binary are helpful in determining if a bottleneck is occurring in performing reconciliation. Abnormally high values or spikes could indicate the control plane is failing to scale, a user is applying excessive pressure on the control plane, or a workload (like an Operator) is misconfigured.
Cloud Controller Manager
Like the Kube Controller Manager, this component also reconciles Kubernetes objects. However, this particular binary focuses on cloud-specific resource reconciliation. When administrators create objects like a Service of type LoadBalancer and PersistentVolumes, they expect AWS Load Balancers and EBS volumes to be created.
The Cloud Controller Manager is responsible for creating these resources based on the schema of the provided Kubernetes objects. Note: most functionality of the Cloud Controller Manager is flagged for deprecation and will be delegated to other Controllers like the AWS Load Balancer Controller and the EBS CSI. Therefore, it may not be worthwhile for administrators to set up monitoring for this binary if their clusters are already running the replacement Controllers.
Kube Scheduler
The Kube Scheduler is responsible for binding incoming Pods to an available worker Node. It will compare the Pod's desired resource specifications (CPU and memory) and check which Nodes have available capacity. It will also apply logic related to affinity, nodeSelectors, and topologySpreadConstraints, which administrators can use to control Pod scheduling.
EKS provides the Scheduler logs and enables administrators to investigate the scheduling decisions being made for Pods. This can be useful when investigating why a particular Pod/Node binding decision was made, which may be necessary to troubleshoot issues related to affinity and Pod spread.
schedule_one.go] "Unable to schedule pod; no fit; waiting" pod="kube-system/coredns-67f8f59c6c-ldnmq" err="0/1 nodes are available: 1 node(s) had untolerated taint {node.kubernetes.io/not-ready: }. preemption: 0/1 nodes are available: 1 Preemption is not helpful for scheduling."
The Prometheus metrics exposed by the Scheduler include how many Pods are waiting for a scheduling decision (scheduler_pending_pods), how long scheduling decisions are taking (scheduler_pod_scheduling_duration_seconds), and how many low-priority Pods are being evicted to make space for higher priority Pods (scheduler_preemption_victims). These metrics can help troubleshoot issues related to pod scheduling delays or identify excessive pod terminations by looking at the eviction metrics. Data from the Scheduler will be useful for determining if the control plane can keep up with the number of Pods being created in the cluster.
etcd
The control plane hosts a database called etcd, which stores the entire state of the EKS cluster. The API Server is exclusively responsible for accessing and modifying items in this database. The etcd binary does not expose any log files for EKS administrators; however, it does expose some Prometheus metrics like the total requests for each object type, the number of errors, and total storage utilization.
There can be control plane issues related to etcd storage exhaustion, which the metrics will help validate. Since this component is critical for a properly functioning cluster, collecting metrics helps ensure control plane issues can be investigated quickly. Note: since administrators can't access the control plane, certain problems may require escalation to AWS Support. Providing metric data to the AWS support engineers will enable them to assist with troubleshooting more effectively.
Enabling control plane monitoring
Administrators can enable EKS control plane logging via the web console and AWS CLI. This will update the EKS cluster to generate CloudWatch Logs containing the information mentioned above. EKS can’t modify the log output target, so CloudWatch is the only option unless the administrator configures other tools to forward CloudWatch Logs to other log ingestion tools.
The metrics for control plane components are exposed at the Kubernetes /metrics endpoint. Any monitoring tool that scrapes Kubernetes metrics will also collect control plane metrics.