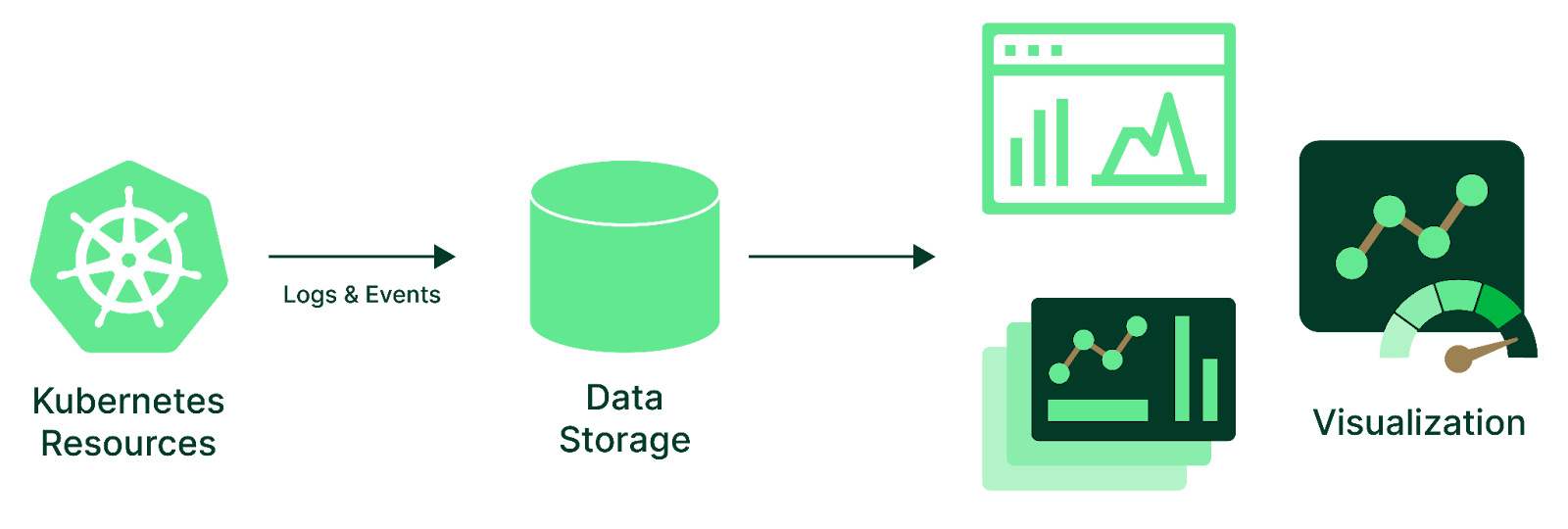
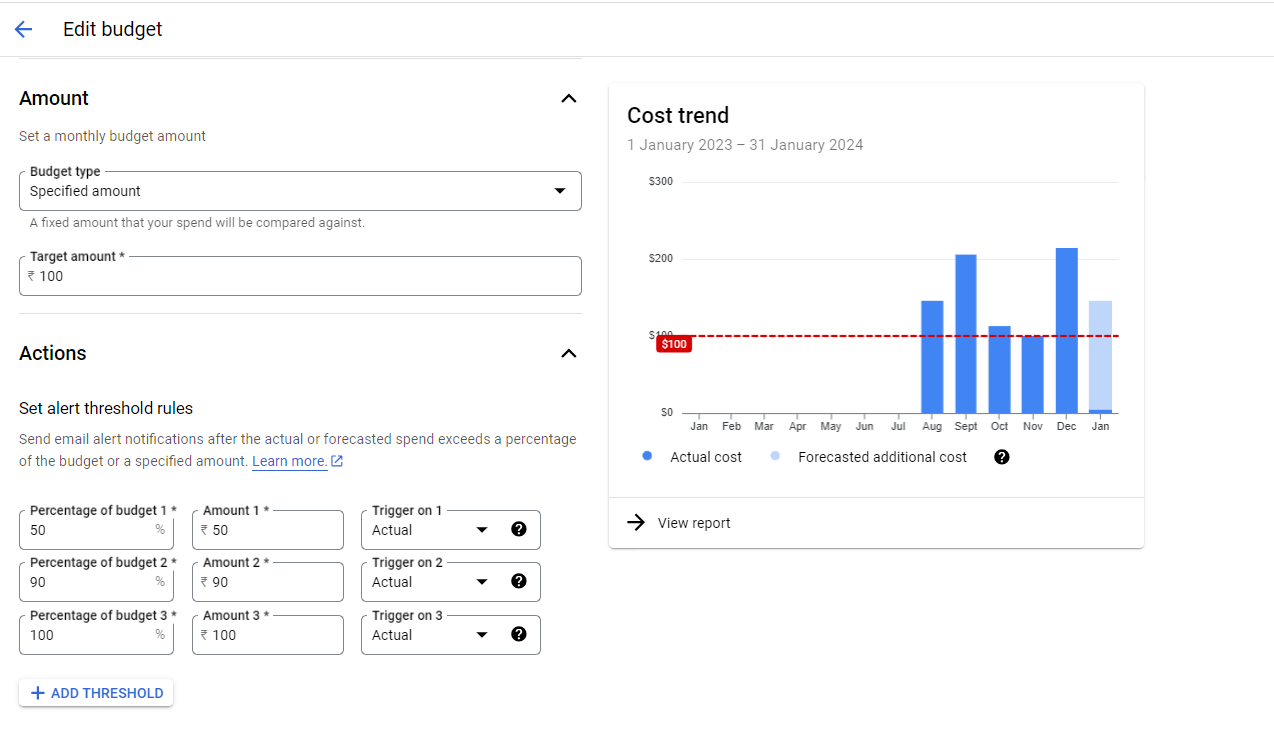
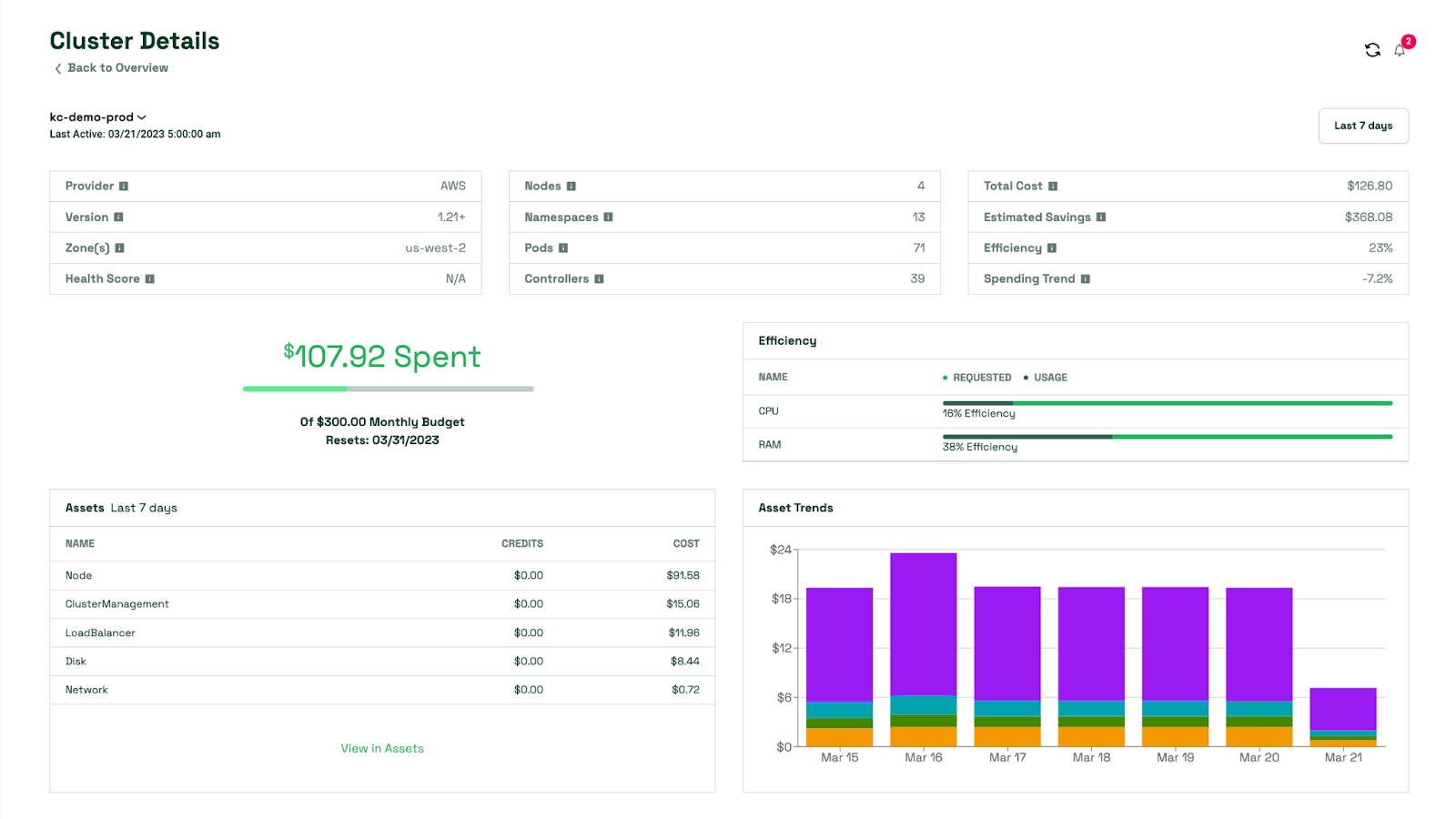
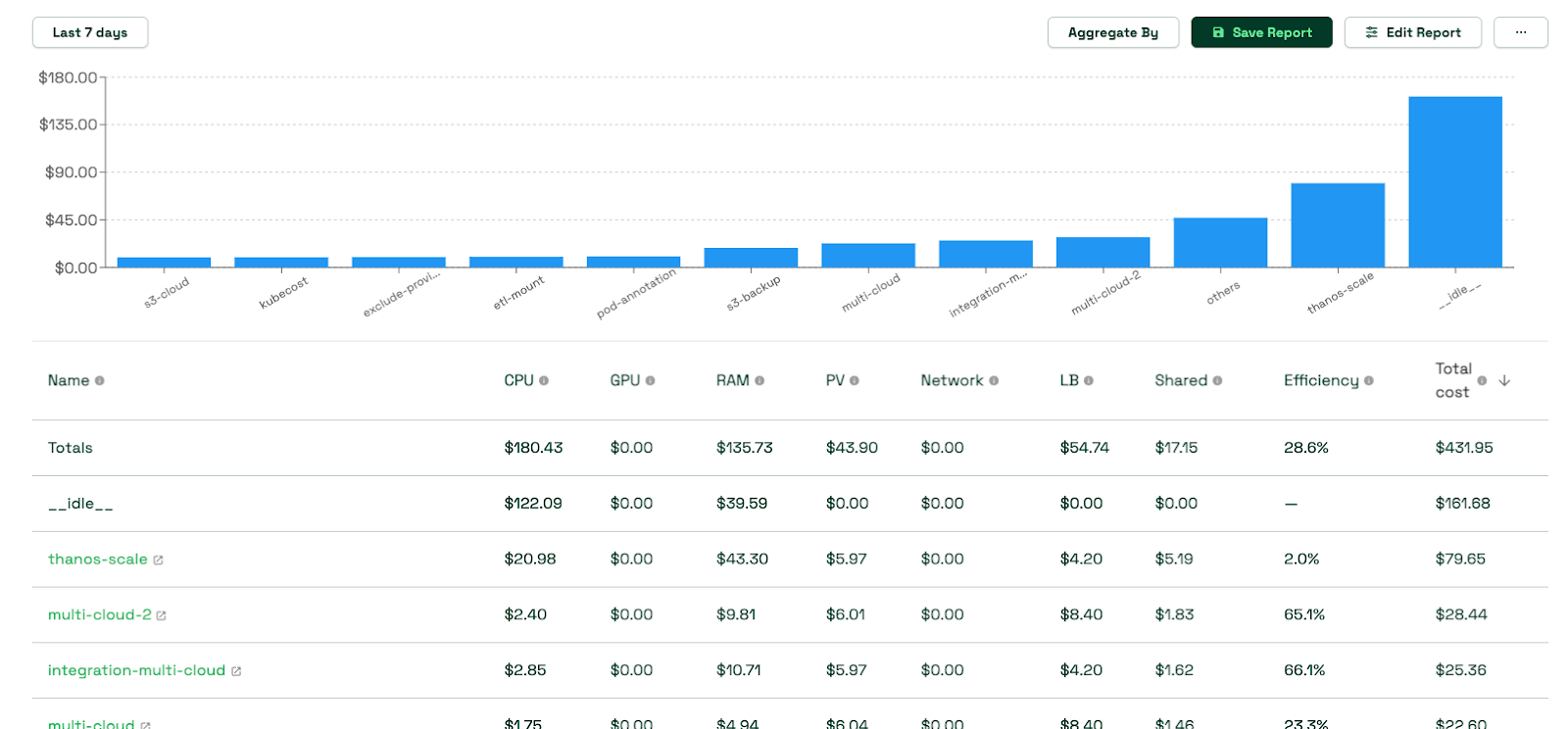
Focus on actionable alerts
Actionable alerts go beyond simply notifying you of an anomaly. They provide context-rich information and clear guidance on remediation, enabling swift and effective response. This includes:
- Precise details: Identifying the affected resource (pod, node, namespace, etc.), the triggering metric (CPU usage, memory pressure, network latency, etc.), the current value and threshold breached, the time of occurrence and duration, and any relevant logs or events.
- Prioritized urgency: Categorizing alerts based on their severity level (critical, high, medium, or low) to ensure immediate attention to the most pressing issues.
- Direct actionability: Including specific steps or automated workflows for addressing the alert, maximizing response efficiency, and minimizing downtime.
Here are some examples of actionable alerts:
- Critical node down:
- Alert title: “Critical Node Outage: Node-3 Unavailable”
- Details: “Node-3 has been unreachable for 5 minutes. Impacted pods: nginx-deployment-7595465465, redis-6546545645. Triggering event: network connectivity loss.”
- Action: “Initiate failover to the backup node. Investigate network connectivity issues.”
- High memory pressure on pod:
- Alert title: “High Memory Usage: frontend-pod-5546546546 (95% Usage)”
- Details: “frontend-pod-5546546546 is experiencing memory pressure exceeding 95% threshold for 10 minutes. Potential performance degradation.”
- Action: “Review pod resource allocation. Consider scaling up resources or optimizing application memory usage.”
These alerts deliver granular details, pinpointing the affected resource and aiding root cause analysis through log data. Additionally, they recommend immediate actions, which help minimize downtime and streamline the response.
Several tools and techniques can be leveraged to implement actionable alerts:
- Prometheus: Utilizing Prometheus Alertmanager enables potent rule-based alerting with flexible notification channels and rich contextual data integration.
- Kubernetes events: Leveraging Kubernetes events offers resource-specific alerts and seamless integration with custom scripts or workflows for automated remediation.
- Other third-party tools: Various third-party tools offer advanced alerting and specialized features such as alert routing, deduplication, escalation, suppression, and enrichment. This ensures that relevant information reaches the right stakeholders while minimizing alert fatigue and improving incident resolution times.
Define optimal alert parameters and thresholds
Setting meaningful alerts and thresholds for resource monitoring in Kubernetes, using Prometheus or a similar tool, is crucial for catching issues and optimizing resource utilization. Here are some considerations for some of the most essential resources:
- CPU: Usage is expected to fluctuate over time. It could spike up to 100% for a short period without issue. High CPU usage becomes an issue when it is sustained at or above a set threshold for an extended period. An example of a reasonable alert threshold would be 80% CPU sustained over five minutes.
- Memory: Monitor for memory leaks, which might look like steady growth in memory usage. Use load testing to determine your application's normal operating memory range and set the threshold above that range. A reasonable threshold for an alert might be closer to 90-95%, and when it’s been there for 1-2 minutes.
- Network: There are numerous metrics you could monitor for network traffic. You should begin with ingress and egress traffic to understand traffic patterns. Once you have established patterns, create alert thresholds that represent anomalies in your environment. This can potentially identify DDoS attacks or a sustained traffic increase, which could translate to higher bandwidth costs.
- Storage: When monitoring storage, you want to know how much is being used, how quickly it is being used, and how fast you can read/write to the system (IOPS). The first two metrics to consider are the overall usage of persistent storage and the rate of change in storage usage. Monitoring the rate of change alongside total usage helps identify potential issues. The third metric (IOPS) will help determine if there are any utilization issues or if disks need to be upgraded to keep up with demand.
Finding suitable thresholds requires a meticulous balance between historical context and real-time benchmarks. If your thresholds are often triggered without them being an issue, consider developing dynamic instead of static thresholds. We will discuss this in the next section.
Dynamic vs. static thresholds
Creating dynamic thresholds involves writing alerting rules that adjust their thresholds based on real-time or historical data rather than fixed static values. This approach allows your alerts to be more adaptable and reduces false positives caused by regular fluctuations in your metrics.
You could use Prometheus and its query language (PromQL) to create dynamic thresholds that adjust based on factors like the rate of change or comparing to the same time one day before.
For example,
groups:
- name: DynamicThresholds
rules:
- alert: CPUUsageHigh
expr: |
max_over_time(node_cpu_seconds_total{mode="idle"}[5m]) < 0.15
for: 10m
annotations:
summary: "High CPU usage detected"
description: "CPU usage exceeded 85% over the last 5 minutes."
Alerting based on change rates
Monitoring the rate changes of key metrics is crucial for proactively identifying potential issues. Implementing the Prometheus rate function aids in tracking these changes:
groups:
- name: RateChangeAlerts
rules:
- alert: CPUUsageSpike
expr: |
rate(node_cpu_seconds_total{mode="idle"}[5m]) > 0.3
for: 5m
annotations:
summary: "Sudden CPU usage spike"
description: "CPU usage increased by more than 30% in the last 5 minutes."
Use alert routing and escalation
Fine-tuning your alert routing and escalation strategy is crucial for a robust Kubernetes incident response. Here are some actions to take:
- Implement tiered notification channels: Escalate alerts based on severity, using low-impact notifications for internal monitoring, SMS for critical issues, and even triggering automated remediation for specific situations.
- Integrate with incident management tools: Integrate an alerting system with incident management platforms like PagerDuty for automated alert ticketing, incident assignment, and collaborative resolution workflows.
- Utilize alert silencing: Define temporary mechanisms for planned maintenance activities or expected fluctuations. This is particularly useful during periods of planned maintenance or upgrades when you know specific alerts will be triggered but are not indicative of a problem.
By implementing these strategies, organizations can ensure that critical alerts reach the right people, fostering a rapid and efficient response to any Kubernetes incident.