These metrics are essential to your business because they can help identify possible improvements to your team or organization’s practices. Such improvements typically involve adjusting spending, such as hiring more people, purchasing new tools, or seeking to adjust cloud resource spending. Here are some examples:
- If the deployment frequency is low, developers might receive friction when gathering requirements. You can improve this by strengthening communication channels among teams (such as using Slack instead of email).
- If the lead time for changes is high, your delivery process may be slow because changes might be getting sluggish or stagnant due to overly complex or manual processes. You can improve this by spending engineering time on accelerating with a continuous delivery (CD) system or by optimizing your current processes.
- If the change failure rate is high, you may need more testing. Slow down feature development to include time for better testing. Fast delivery doesn’t mean much if what you produce is brittle or doesn’t work.
- If the time to restore service number is high, your software or infrastructure might have performance issues. You can put systems in place to keep a paper trail when things go wrong, such as storing logs, performance monitoring, debugging, etc.
Looking beyond SDLC, improving DORA metrics improves software reliability, providing the features and availability the customer expects.
Kubernetes mechanisms
Liveness probes. Readiness probes. Resource limits and requests. While these are only a minor aspect of this article, please, please, please use them. They are critical tools that Kubernetes uses to manage pods.
Liveness and readiness probes tell Kubernetes what to do if your app becomes unhealthy. Readiness probes tell Kubernetes that the app is ready to receive traffic and are also used to help with a safe rollout. Pro tip: As a rule of thumb, set the time of your liveness probes to twice the time of your readiness probes.
Kubernetes uses many factors to determine which nodes to place pods on. For your workload, the most significant factors are the resource limits and requests you define for your pods. If not set up correctly, your app may not get all the resources it needs, may unintentionally take resources away from other applications, or might not get scheduled at all.
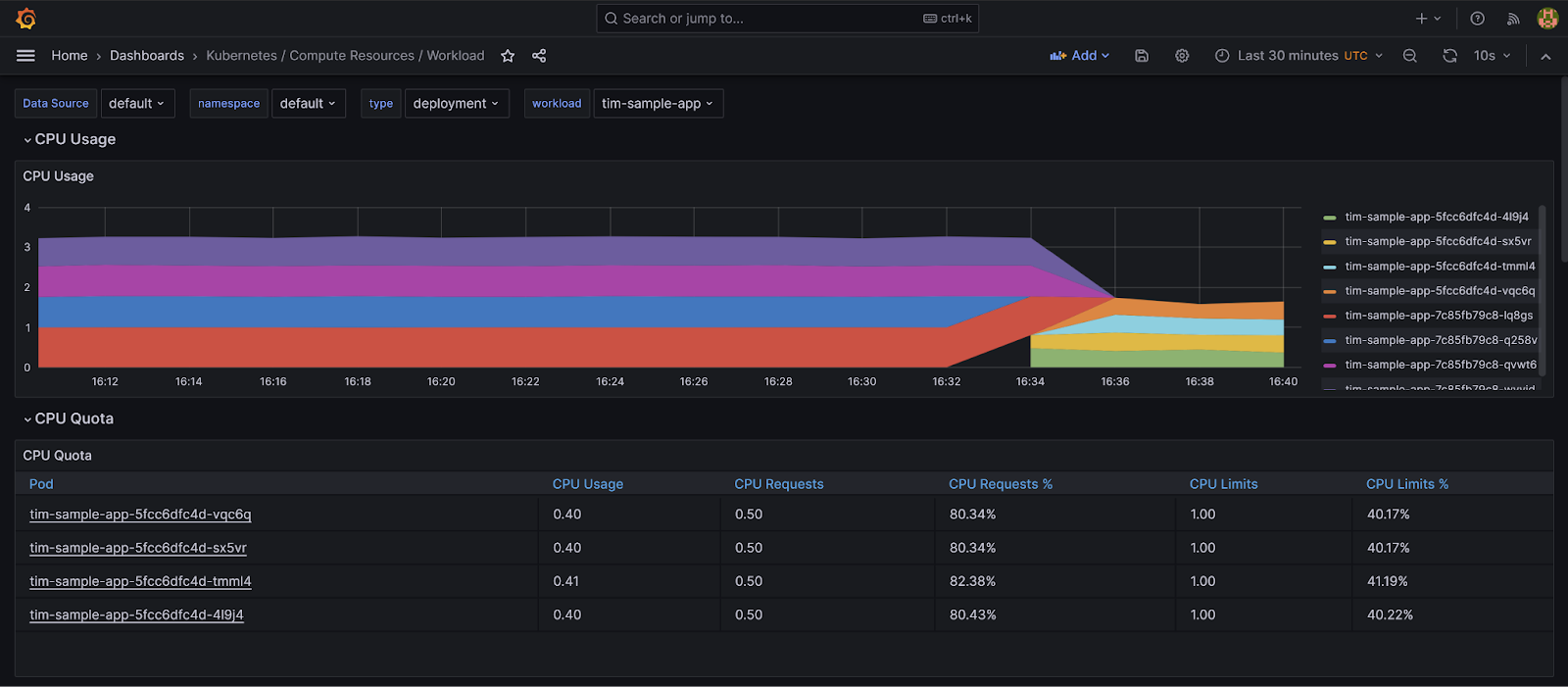
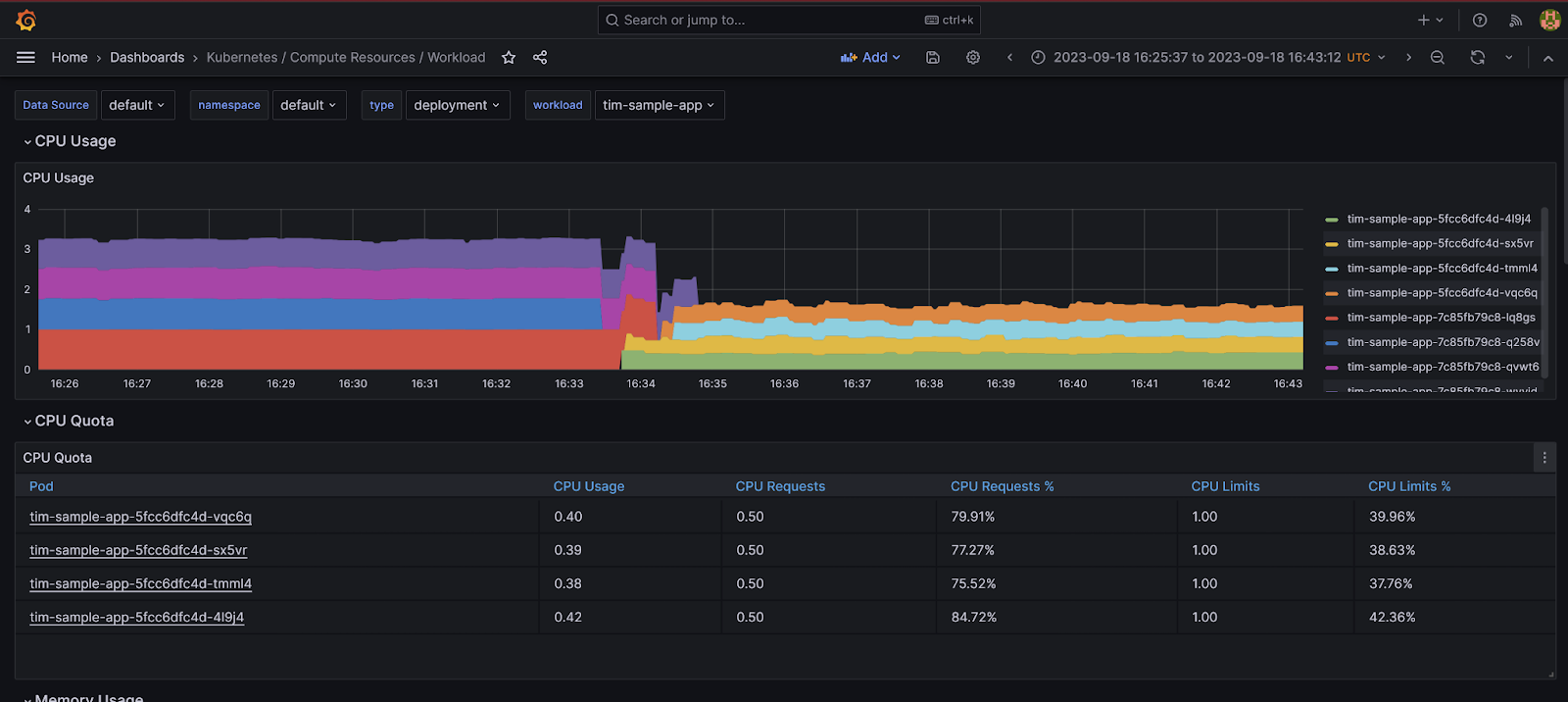
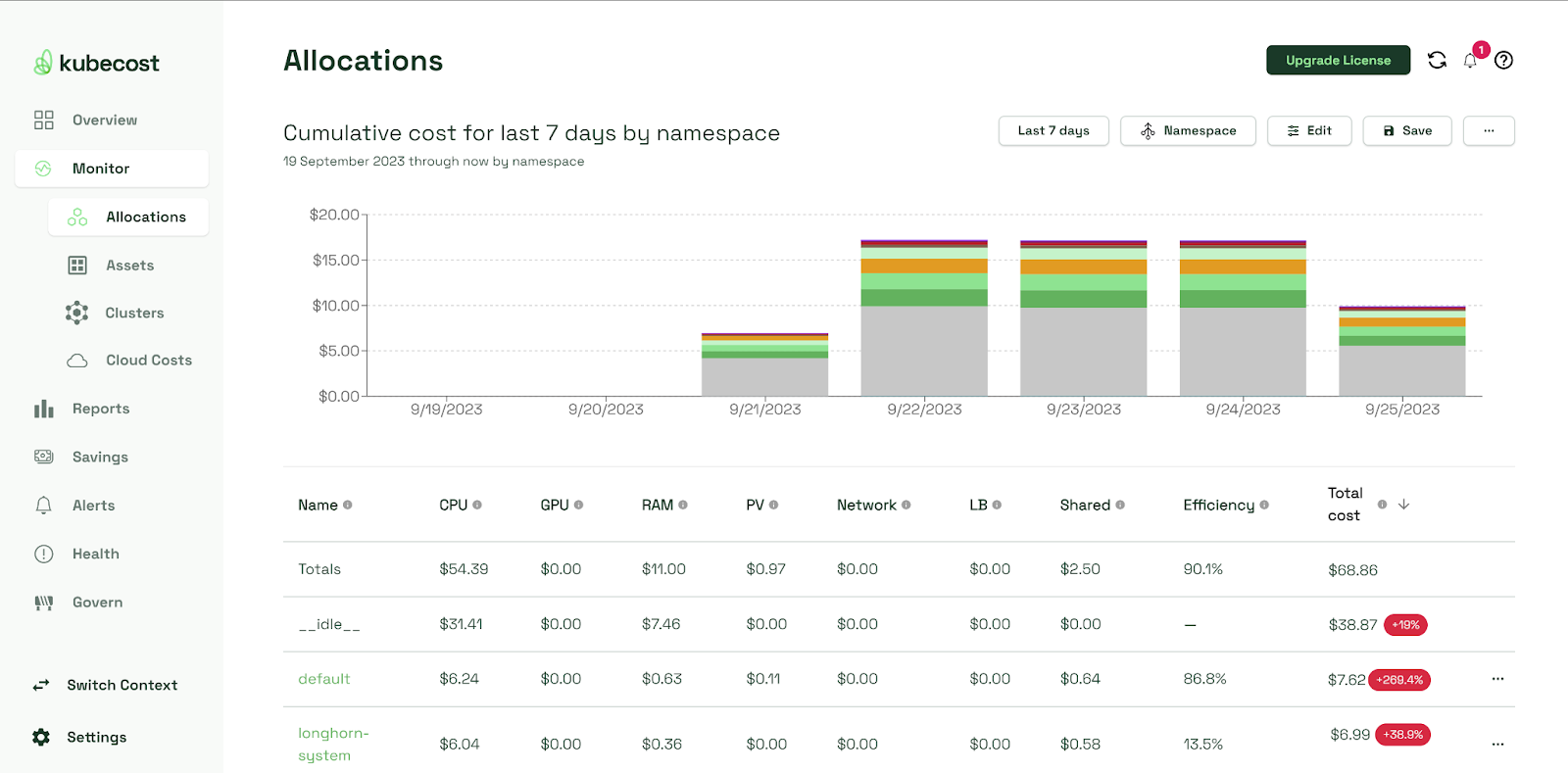
Grafana monitoring dashboards
The monitoring dashboards are crucial when trying to improve your DORA metrics. These dashboards provide valuable metrics, such as CPU and memory, for the whole cluster, nodes, namespaces, workloads, and pods, as well as performance metrics for other Kubernetes resources, such as the API server.
Grafana in practice
In 2016, AT&T began adopting Kubernetes. The Elasticsearch team was tasked with deploying the Elastic stack inside Kubernetes as the logging system for every cluster.
Early in the project, it was reported that Elasticsearch ran for about a day and then crashed every five minutes continually. The team was puzzled because they had never seen behavior like this in their non-Kubernetes environments.
Looking at Grafana, they could see that it was slowly increasing its memory usage over about 24 hours, then hitting the memory limit and crashing. It then loaded back up but quickly ramped up again to the memory limit and crashed, doing so repeatedly. Deleting the pod worked, but eventually, another one would do the same thing.
It took them a few months to get to the bottom of the issue, which was complicated and complex to resolve. The Grafana dashboard provided a starting point for understanding the nature of the issue and became the anchor for its resolution.